Datamining
- This is some work with Viviane Orengo and we've submitted it to
the Neural Computing and Applications Journal.
- We did two tasks: the congressional voting task and information
retrieval
- Congressional Voting
- From the Cal
Irvine Database
- Given the voting records on 16 bills of US congresspeople,
categorise whether they are Republican or Democratic.
- It's supervised and they can abstain.
- We did a 5-fold validation.
- We got about 89% of them if we trained on 80% and tested on 20%
and about 86% in the reverse condition.
- Prior work indicates that the best possible result is between
90 and 95 (Schlimmer's PhD thesis).
- Information Retrieval
- Viviane Orengo has just finished her PhD in Information
Retrieval (using LSI and cross-linguistically).
- For this paper, she used a couple of standard IR tasks, the Time
Magazine collection and the Cranfield collection.
- She stemmed the text of 425/1400 documents, with 83/225
queries, and 7596/2629 terms.
- Each term in more than one document was assigned
a neuron and each neuron had 40 synapses leaving it.
- We trained by presenting each document 20 times.
- We tested by activating words in the query and
letting activation spread for 5 cycles.
- We then did a Pearson's comparison to all of the
document networks (computationally expensive).
- The results with a compensatory rule were 40%/28% on the
Cranfield test
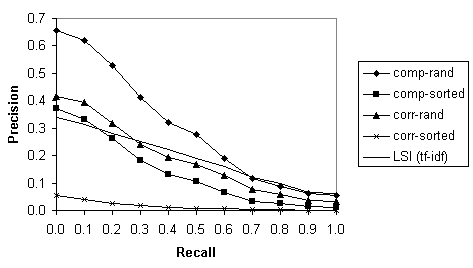
- LSI is a standard technique and we (somewhat surprisingly)
do better than it.
- Note that the compensatory rule really has the same
effect as the standard IR measure of term frequency
inverse document frequency (TF-IDF).


